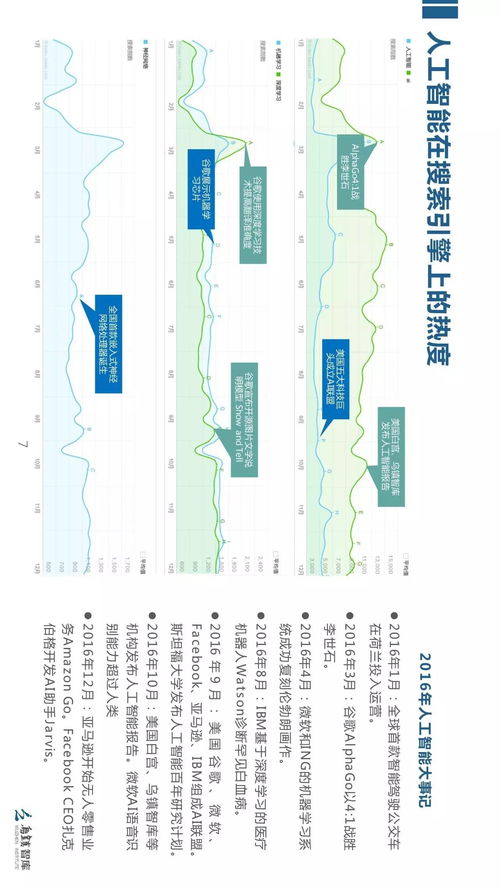
引言
2024年,全球人工智能领域正经历一场由大模型驱动的深刻变革。以GPT、Claude、Gemini、Llama等为代表的预训练大模型,正从实验室走向千行百业,重塑着人工智能应用软件(AI-Enabled Software)的开发范式、技术架构与商业模式。本报告旨在系统梳理当前大模型全栈技术生态,深入分析其对AI应用软件开发带来的机遇与挑战,并展望未来发展趋势。
一、 大模型技术栈全景:从基础设施到上层应用
AI大模型的全栈技术可划分为四个关键层级:
- 算力基础设施层:以英伟达(GPU)、AMD、谷歌(TPU)及众多云服务商(AWS、Azure、GCP、阿里云、腾讯云等)为核心,提供模型训练与推理所必需的强大算力。2024年的焦点是推理优化,通过专用芯片(如NPU)、模型压缩、量化技术大幅降低部署成本。边缘计算与大模型的结合也成为新热点。
- 模型与平台层:
- 基础大模型:闭源与开源路线并行。闭源模型(如GPT-4、Claude 3)追求性能极限;开源模型(如Llama 3、Qwen、DeepSeek)在透明性、可控性和定制化方面优势显著,成为企业私有化部署的主流选择。
- 模型平台/市场:Hugging Face、Replicate、ModelScope等平台汇聚了海量模型,提供一站式的模型发现、微调、评估与部署服务,极大降低了模型获取与使用的门槛。
- MaaS(模型即服务):云厂商将大模型能力封装为API服务,是快速构建AI应用的最便捷路径。
- 开发与工具层:这是连接大模型能力与具体应用场景的核心环节。
- 提示工程与上下文优化:System Prompt设计、思维链(CoT)、Few-shot Learning等技术是高效激发模型能力的基础。
- 检索增强生成(RAG):通过将外部知识库(如企业文档、数据库)与大模型结合,有效解决模型幻觉、知识过时和专有知识不足的问题,已成为构建企业级AI应用的“标配”架构。
- 智能体(Agent)框架:LangChain、LlamaIndex、AutoGen等框架通过赋予大模型使用工具(搜索、计算、API调用)、规划任务、执行多步推理的能力,使AI应用从“聊天机器人”升级为能够自主完成复杂任务的“智能工作流”。
- 微调与持续训练:LoRA、QLoRA等参数高效微调技术,使得企业能以较低成本,利用自有数据对基础模型进行领域适配和性能优化。
- 应用层:基于上述技术栈,AI应用软件正在各个领域落地开花:
- 生产力工具:Copilot形态已渗透至代码开发(GitHub Copilot)、办公软件(Microsoft 365 Copilot)、设计(Adobe Firefly)等。
- 垂直行业解决方案:金融风控、医疗辅助诊断、法律文书分析、教育个性化辅导等场景的专用AI应用。
- 新一代交互界面:自然语言成为新的操作系统和交互范式,催生了AI助手、对话式分析平台等。
二、 人工智能应用软件开发范式的根本性转变
大模型技术栈的成熟,使得AI应用软件开发呈现出与传统软件及早期AI应用截然不同的新范式:
- 从“模型中心”到“应用中心”:开发者无需从零开始训练复杂的专用模型,而是基于强大的基础模型,聚焦于提示工程、知识库构建、工作流编排和用户体验设计。开发的核心从“炼丹”转向“组装”和“引导”。
- 从“确定性的程序逻辑”到“概率性的交互协作”:传统软件遵循严格的if-else逻辑。大模型应用则需处理非确定性的输出,开发重点转向设计评估、校验、纠错和人工反馈(RLHF) 的机制,确保系统的可靠性与安全性。
- 从“功能实现”到“价值对齐与合规”:随着应用深入核心业务,可解释性、公平性、数据隐私(GDPR等)、版权合规(训练数据来源) 成为产品设计与开发中必须前置考量的关键要素。AI治理与安全框架的构建变得至关重要。
- 开发门槛的双重性:一方面,借助高阶API和框架,原型验证和简单应用开发的门槛大幅降低;另一方面,要构建稳定、高效、可扩展的企业级生产系统,需要对大模型原理、分布式系统、成本优化有深刻理解的全栈AI工程师,人才门槛反而提高。
三、 关键挑战与应对策略
- 成本与性能的平衡:大模型推理成本高昂,响应延迟可能影响体验。策略包括:
- 模型选型:根据场景选择“大小模型混合”策略,简单任务用小模型或专用模型,复杂任务用大模型。
- 缓存与优化:对常见查询结果进行缓存,使用量化、剪枝等技术压缩模型。
- 异步与流式处理:对非实时任务采用异步处理,对长文本生成采用流式输出。
- 可靠性(幻觉与事实性):
- RAG架构的深度应用:确保回答严格基于提供的权威知识源。
- 多步验证与溯源:要求模型提供引用来源,或设计交叉验证流程。
- 领域微调:在高质量领域数据上微调,提升模型的领域认知准确性。
- 数据安全与隐私:
- 私有化部署:采用开源模型在自有基础设施上部署。
- 数据脱敏与加密:在调用外部API前对敏感信息进行处理。
- 合规的数据处理协议:明确训练、微调数据的所有权和使用边界。
- 技术迭代速度与工程化:技术栈日新月异,要求团队保持快速学习能力,并建立稳健的MLOps for LLM(大模型运维)体系,涵盖模型的版本管理、监控、A/B测试和持续迭代。
四、 2024年趋势展望
- 小型化与专业化:追求极致的性能/成本比,催生更多针对特定场景优化的小型专家模型(Small Language Models, SLMs)。
- 多模态成为标配:图文、音视频理解与生成能力深度集成,使AI应用能处理更丰富的现实世界信息。
- 智能体(Agent)生态爆发:具备自主规划与执行能力的智能体将从演示走向实用,在客服、游戏、科研、自动化流程中扮演核心角色。
- AI原生应用重构工作流:不再是“为旧流程添加AI功能”,而是诞生完全基于自然语言交互、由AI协同人类重新设计的“AI原生”应用,彻底改变软件形态。
- 标准化与开源治理:模型接口、评估基准、安全规范将逐步形成行业标准;开源社区在推动技术民主化和建立可信AI方面作用愈发关键。
结论
2024年,全球AI大模型技术栈已进入深化应用与产业融合的关键期。人工智能应用软件开发的核心竞争,正从单纯的模型能力比拼,转向对行业知识的深度理解、对技术栈的娴熟集成、对复杂系统工程的把控能力,以及对负责任AI的坚定实践。成功者将是那些能最快将大模型的“通用智能”潜力,转化为解决具体业务痛点、创造真实用户价值的“专用智能”解决方案的团队与企业。全栈技术是基石,而真正的黄金位于垂直应用的深处。